Applied AI
Production RAG in Next.js: What Actually Breaks After Launch
Feb 24, 2026 · 7 min read
Most RAG demos fail for boring reasons: weak retrieval control, no eval loop, no traceability, and bad trust UX. Here is the production shape I use instead.

Most RAG demos fail in the same place
Most RAG demos do not fail because the model is weak. They fail because the team never built a system around the model.
The demo looks good because it answers a happy-path question against a small, clean dataset. Production looks different:
- users ask vague questions,
- sources get stale,
- documents disagree with each other,
- latency starts to matter,
- and the cost of one confident wrong answer becomes real.
That is the gap most teams underestimate.
They think they are shipping "a better prompt". What they are actually shipping is a decision system:
- what content enters the index,
- what gets retrieved,
- what the model is allowed to say,
- how the UI shows uncertainty,
- and how the team detects regressions later.
If those parts are weak, no prompt save is coming.
When RAG stopped feeling like a prompt
The project that made this obvious for me was Fotelik.
Fotelik is an AI-assisted political matching product built around a custom quiz, structured research, scoring, retrieval, and explainable results. That domain is useful because it removes the usual RAG fantasy.
You cannot hide behind "good enough" wording when:
- the topic is sensitive,
- the user expects provenance,
- and the result has to be explainable, not just plausible.
In that project I was not just wiring a model into a UI. I had to build the full surface around it:
- an AI-assisted pipeline that turned public political content into structured summaries,
- embeddings and
pgvectorstorage for semantic retrieval, - human-in-the-loop internal tooling for scraping, extraction, scoring, embedding, and search,
- and answer flows with grounding, schema constraints, and explainability.
That is where my view on RAG changed.
Reliable RAG is not "LLM + vector DB". It is five layers of control that have to agree with each other.
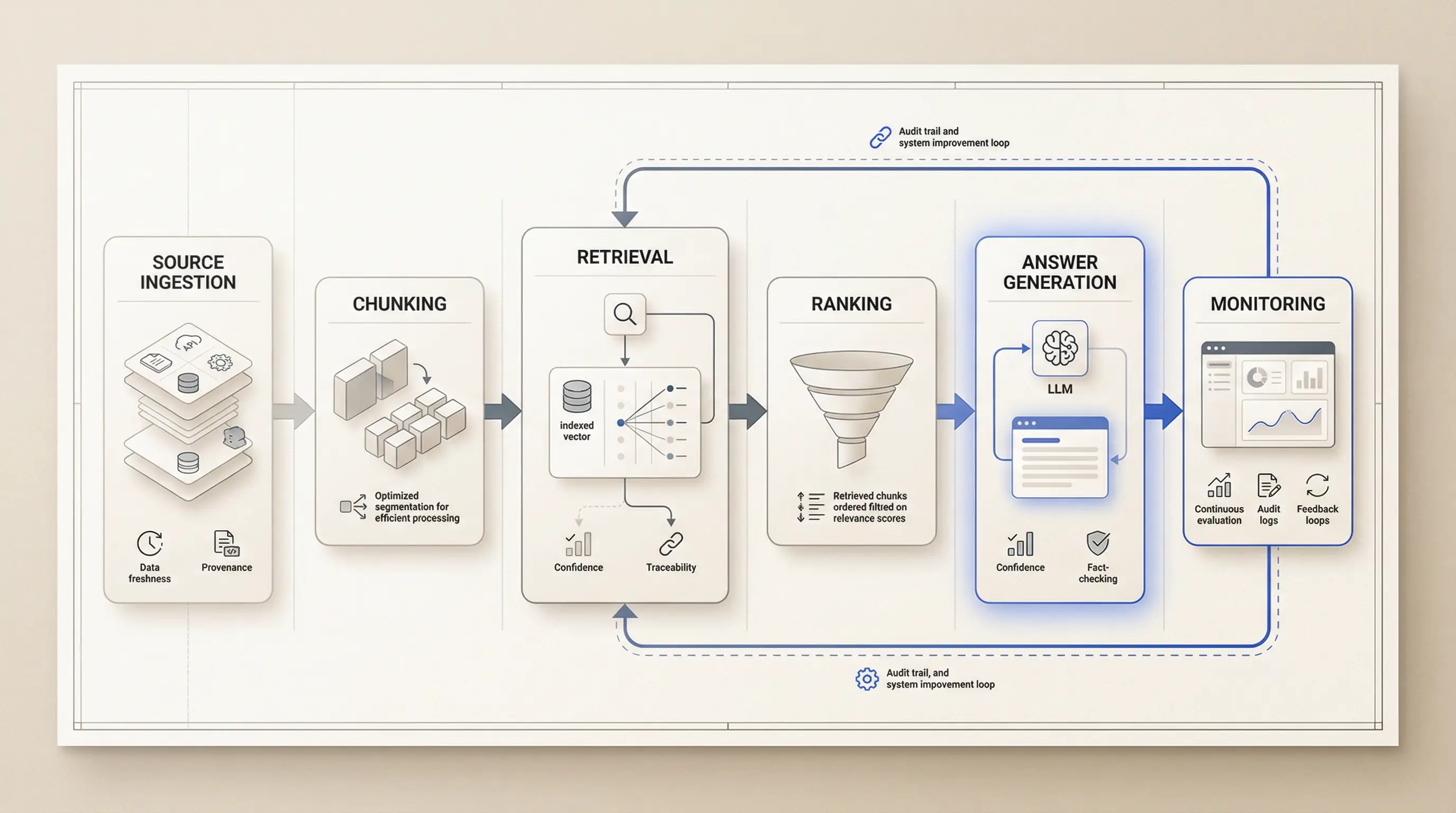
Layer 1: ingestion decides what truth exists
Most RAG discussions start too late. They start at retrieval or prompting.
The real quality story starts at ingestion.
If your source pipeline is messy, your retrieval layer will be messy in a more expensive way. Bad chunks, missing metadata, stale documents, duplicated records, and weak normalization all show up later as "model quality" complaints.
In practice, each chunk should know at least:
- where it came from,
- when it was last updated,
- what language or scope it belongs to,
- and whether it is safe to use in the answer path.
That sounds boring. It is also the difference between a system you can debug and a system you can only argue about.
In a project like Fotelik, I could not let raw extraction output flow straight into public-facing answers without control. The moment the topic is sensitive, provenance stops being a nice-to-have.
My rule is simple:
If the team cannot explain how a chunk entered the system, that chunk should not be trusted in a critical answer.
Layer 2: retrieval is the product, not plumbing
Many teams still treat retrieval as plumbing. Embed the docs, run similarity search, ship.
That is enough for a demo. It is not enough for a product.
Real retrieval quality depends on decisions like:
- chunk size,
- metadata quality,
- filter design,
- freshness rules,
- hybrid search or lexical fallback,
- reranking,
- and logging why a source was selected.
This is where a lot of "prompt tuning" work is wasted. Teams keep rewriting prompts to compensate for weak retrieval. The result is a nicer-looking answer built on the same shaky context.
The better order is:
- measure retrieval quality first,
- improve context quality,
- then tune generation.
If the wrong documents reach the model, the prompt is now solving the wrong problem.
That is why I like separating two questions:
- Did we retrieve the right evidence?
- Did we turn that evidence into a good answer?
If you do not separate them, every failure turns into vague debugging.
Layer 3: the answer path needs constraints, not vibes
Once retrieval works, teams often relax too early. They see relevant context arrive and assume the answer is now safe.
It is not.
The answer layer still needs rules:
- when the model should answer,
- when it should refuse,
- when it should ask for clarification,
- what structure the output must follow,
- and how sources are attached to claims.
This is where schema constraints and explicit answer contracts become useful.
In politically sensitive or high-trust domains, I would rather get a narrower answer with a clear source trail than a broad answer that "sounds smart".
You do not need a huge framework for this. You need a contract that makes the system legible.
For example, even a thin trace record gives you much better control:
type RagTrace = {
query: string;
promptVersion: string;
model: string;
sources: Array<{ docId: string; score: number; updatedAt?: string }>;
latencyMs: number;
outcome: "grounded" | "low_confidence" | "fallback" | "error";
};
If you are not logging something like this, you are not operating a RAG system. You are hoping it behaves.
Layer 4: trust UX matters as much as relevance
Even a technically correct answer can fail as a product if the UI communicates false certainty.
This is where many RAG systems lose trust:
- sources are hidden,
- low-confidence answers look identical to grounded ones,
- fallback states are vague,
- and the user has no clean recovery path.
For me, trust UX is part of RAG quality. Not a separate design polish step.
The user should be able to understand:
- what the system used,
- what it could not verify,
- and what to do next.
That usually means:
- source links near important claims,
- a visible "I do not know" path,
- suggested refinements when confidence is low,
- and honest fallback states for timeouts or missing context.
If the UI hides uncertainty, the system teaches users the wrong lesson. They stop trusting it not because it was wrong once, but because it looked certain when it should not have.
That is why I do not separate retrieval quality from UX quality. In real usage they collapse into the same question:
Can the user trust this answer enough to act on it?
Layer 5: no eval loop, no production
This is the layer missing from most public RAG projects.
A lot of teams say they "tested it". What they mean is that they asked a few questions manually.
That is not enough once:
- prompts change,
- models change,
- source documents change,
- chunking changes,
- or a new retrieval rule lands.
At minimum, I want:
- a benchmark set of real questions,
- a way to inspect retrieval hit quality,
- a grounded answer check,
- a latency budget by stage,
- and a visible fallback rate.
You do not need a giant platform to start. Thirty real queries are already more useful than a hundred opinions.
The point is not perfect measurement. The point is being able to say:
- this change improved retrieval,
- this change hurt grounded answers,
- this prompt version increased fallback rate,
- this model upgrade added cost without improving trust.
That is what "production-minded" means in practice.
Where Next.js 16 actually helps
Next.js does not solve RAG for you. That is good.
What it gives you is a clean shell for drawing boundaries:
- App Router for stable page structure,
- Route Handlers for mutable AI work,
- explicit cache and revalidation controls,
- and a good fit for streaming responses when you want them.
In Next.js 16, the main lesson is not "use this one RAG pattern". It is: be explicit about what is static, what is dynamic, and what freshness guarantees matter.
That usually means:
- static or revalidated content where the data can tolerate caching,
- dynamic answer routes where freshness and user input drive the work,
- and clear separation between ingest/admin flows and public answer flows.
If you use the Vercel AI SDK for streaming, that can make the route-handler side cleaner. But the tooling choice matters less than the system boundary.
Next.js gives you the application shell. It does not give you:
- retrieval quality,
- eval coverage,
- provenance rules,
- or trust UX.
Those are still your job.
The smallest release gate I would accept
Before I would call a RAG feature production-ready, I want to see all of this:
- A known ingestion path with metadata and freshness rules.
- A benchmark set of real user questions.
- A trace record for every answer path.
- A low-confidence or refusal state in the UI.
- A latency budget that someone actually watches.
- A human owner for source quality and system behavior.
That is not enterprise theater. That is the minimum structure that stops the system from drifting into folklore.
Without it, teams keep having the same meeting:
"The model seems worse this week."
That sentence usually means:
- nobody measured retrieval,
- nobody tracked the answer path,
- and nobody knows whether the regression came from the model, the prompt, or the source data.
What I would tell a founder shipping RAG now
Do not ask first, "Which model should we use?"
Ask:
- what evidence will this system use,
- how will we know it used the right evidence,
- what will the user see when confidence is low,
- and how will we detect regressions after launch.
If you can answer those questions, the model choice becomes easier. If you cannot, the model choice is still premature.
That is the real shape of production RAG in Next.js. Not a clever prompt. Not a vector database screenshot.
A system that can explain:
- why it answered,
- what it used,
- when it should refuse,
- and how the team knows when quality drops.
That is the bar I care about. And it is the bar I want my portfolio to prove.
Key takeaways
- Most RAG failures happen before prompt quality matters: ingestion, retrieval, freshness, and trust UX break first.
- If you cannot inspect the answer path with evals and traces, you do not really control the system.
- In sensitive domains, provenance and refusal behavior matter more than impressive wording.
- Next.js gives a clean shell for production RAG, but the real work is the system around retrieval and user trust.
References
Want this quality level in your product?
I help teams ship AI features that are fast, trustworthy, and production-ready.