Applied AI
Produkcyjny RAG w Next.js: co naprawde psuje sie po wdrozeniu
Feb 24, 2026 · 7 min read
Wiekszosc demo RAG pada z nudnych powodow: slaba kontrola retrievalu, brak evali, brak trace'ow i zly UX zaufania. Oto ksztalt systemu, ktory ma sens w produkcji.

Wiekszosc demo RAG psuje sie w tym samym miejscu
Wiekszosc demo RAG nie przegrywa dlatego, ze model jest za slaby. Przegrywa dlatego, ze zespol nie zbudowal systemu wokol modelu.
Demo wyglada dobrze, bo odpowiada na jedno ladne pytanie na malym, czystym zbiorze danych. Produkcja wyglada inaczej:
- user zadaje niejednoznaczne pytania,
- zrodla sie starzeja,
- dokumenty sobie przecza,
- latencja zaczyna miec znaczenie,
- a koszt jednej pewnej, ale blednej odpowiedzi staje sie realny.
To jest luka, ktorej wiele zespolow nie doszacowuje.
Mysla, ze wdrazaja "lepszy prompt". W praktyce wdrazaja system decyzji:
- co wchodzi do indeksu,
- co zostaje wybrane przez retrieval,
- co modelowi wolno powiedziec,
- jak UI pokazuje niepewnosc,
- i jak zespol wykrywa regresje po wdrozeniu.
Jesli te warstwy sa slabe, zaden prompt nie uratuje wyniku.
Moment, w ktorym RAG przestal byc dla mnie "promptem"
Projekt, ktory ustawil mi to najmocniej, to Fotelik.
Fotelik to AI-assisted political matching product oparty o custom quiz, strukturyzowany research, scoring, retrieval i explainable results. Ta domena jest dobra, bo szybko zabiera zludzenia.
Nie da sie schowac za "good enough", kiedy:
- temat jest wrazliwy,
- user oczekuje provenance,
- a wynik ma byc wyjasnialny, a nie tylko przekonujacy.
W tym projekcie nie podpialem po prostu modelu do UI. Musialem zbudowac caly system wokol odpowiedzi:
- pipeline AI-assisted, ktory zamienial publiczne tresci polityczne na strukturyzowane podsumowania,
- embeddings i
pgvectordo semantic retrievalu, - human-in-the-loop tooling do scrape'u, ekstrakcji, scoringu, embeddingu i searchu,
- oraz answer flow z groundingiem, schema constraints i explainability.
Wlasnie tam zmienilo mi sie myslenie o RAG.
Rzetelny RAG to nie jest "LLM + vector DB". To jest piec warstw kontroli, ktore musza sie ze soba zgadzac.
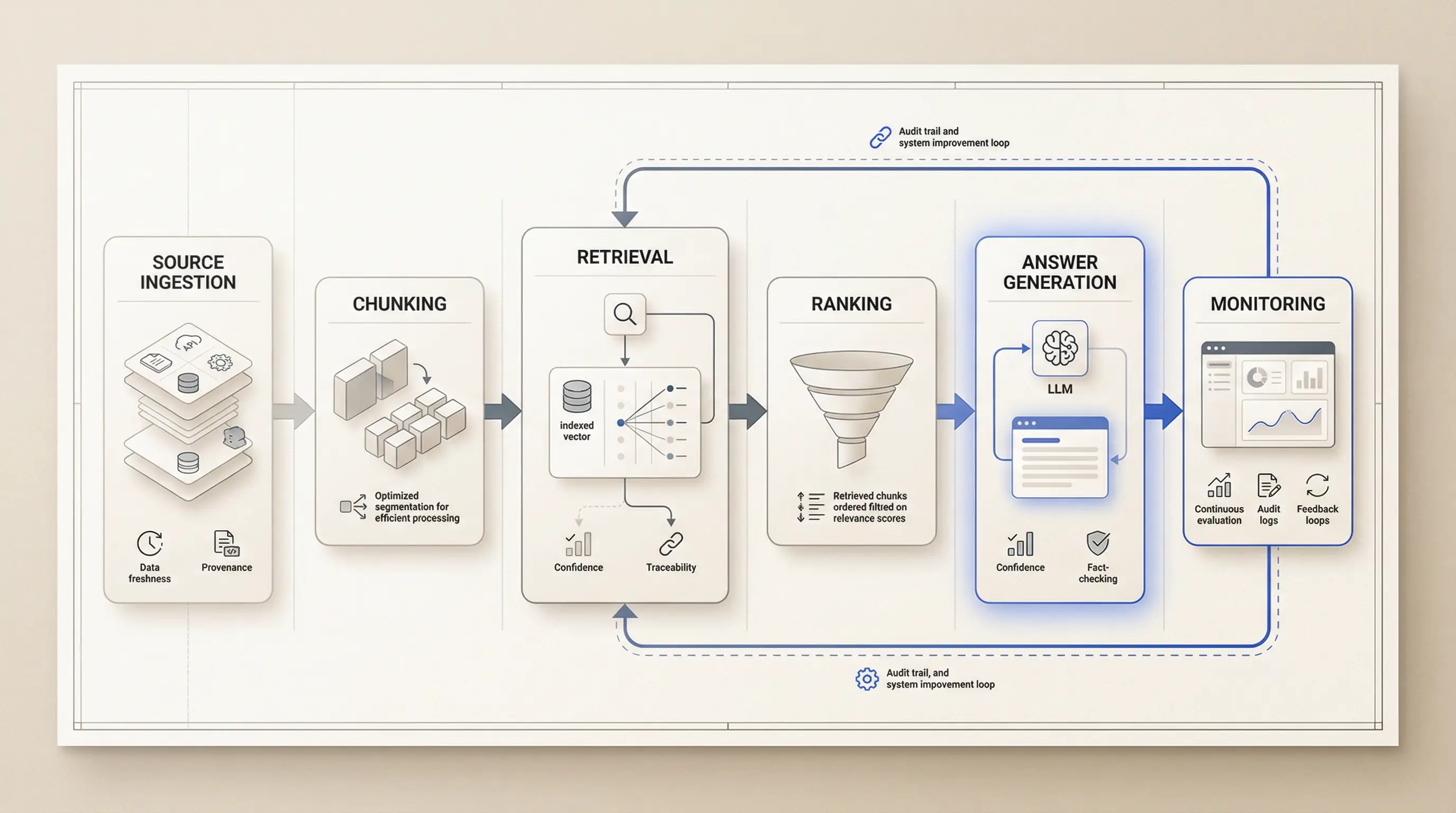
Warstwa 1: ingestia decyduje, jaka "prawda" istnieje w systemie
Wiekszosc rozmow o RAG zaczyna sie za pozno. Zaczyna sie od retrievalu albo promptu.
Prawdziwa historia jakosci zaczyna sie od ingestii.
Jesli pipeline zrodel jest brudny, to retrieval bedzie brudny w drozszy sposob. Zle chunki, brak metadanych, stare dokumenty, duplikaty i slaba normalizacja wracaja pozniej jako "problem modelu".
W praktyce kazdy chunk powinien wiedziec przynajmniej:
- skad pochodzi,
- kiedy byl ostatnio zaktualizowany,
- do jakiego jezyka albo scope'u nalezy,
- i czy jest bezpieczny dla publicznej sciezki odpowiedzi.
To brzmi nudno. I bardzo dobrze.
To jest roznica miedzy systemem, ktory da sie debugowac, a systemem, o ktorym da sie tylko dyskutowac.
W projekcie takim jak Fotelik nie moglem wypuscic surowego outputu z ekstrakcji prosto do odpowiedzi usera. W chwili, gdy domena jest wrazliwa, provenance przestaje byc opcja.
Moja zasada jest prosta:
Jesli zespol nie umie wyjasnic, jak chunk wszedl do systemu, to nie powinien mu ufac w krytycznej odpowiedzi.
Warstwa 2: retrieval jest produktem, a nie plumbingiem
Wiele zespolow nadal traktuje retrieval jak plumbing. Zrob embeddings, wrzuc similarity search, ship.
To wystarcza na demo. Nie wystarcza na produkt.
Jakosc retrievalu zalezy od decyzji takich jak:
- rozmiar chunka,
- jakosc metadanych,
- projekt filtrow,
- zasady swiezosci,
- hybrid search albo lexical fallback,
- reranking,
- i logowanie, dlaczego dane zrodlo zostalo wybrane.
Tutaj marnuje sie duzo pracy nad "prompt tuningiem". Zespoly poprawiaja prompt, zeby zamaskowac slaby retrieval. Efekt jest taki, ze odpowiedz brzmi lepiej, ale stoi na tym samym slabym kontekscie.
Lepsza kolejnosc jest taka:
- najpierw mierz jakosc retrievalu,
- potem poprawiaj kontekst,
- dopiero na koncu strojenie generacji.
Jesli do modelu trafiaja zle dokumenty, prompt rozwiazuje zly problem.
Dlatego lubie oddzielac dwa pytania:
- Czy retrieval znalazl dobre evidence?
- Czy model zamienil to evidence w dobra odpowiedz?
Bez tego kazda porazka zamienia sie w mglisty debugging.
Warstwa 3: sciezka odpowiedzi potrzebuje constraints, nie "vibes"
Kiedy retrieval zaczyna dzialac, zespoly zbyt szybko odpuszczaja. Widzą trafny kontekst i zakladaja, ze odpowiedz jest juz bezpieczna.
Nie jest.
Warstwa odpowiedzi dalej potrzebuje zasad:
- kiedy model ma odpowiedziec,
- kiedy ma odmowic,
- kiedy ma doprecyzowac pytanie,
- jaki ksztalt ma miec output,
- i jak zrodla sa przypinane do claimow.
W tym miejscu schema constraints i jawny answer contract zaczynaja miec sens.
W polityce albo innych high-trust domenach wole wezsza odpowiedz z czystym source trail niz szeroka odpowiedz, ktora po prostu "brzmi madrze".
Nie potrzebujesz do tego wielkiego frameworka. Potrzebujesz kontraktu, ktory robi system czytelnym.
Nawet cienki trace record daje duzo lepsza kontrole:
type RagTrace = {
query: string;
promptVersion: string;
model: string;
sources: Array<{ docId: string; score: number; updatedAt?: string }>;
latencyMs: number;
outcome: "grounded" | "low_confidence" | "fallback" | "error";
};
Jesli nie logujesz czegos w tym stylu, to nie operujesz systemem RAG. Po prostu liczysz, ze bedzie sie dobrze zachowywal.
Warstwa 4: UX zaufania jest tak samo wazny jak relevance
Nawet technicznie poprawna odpowiedz moze przegrac jako produkt, jesli UI komunikuje falszywa pewnosc.
W tym miejscu wiele systemow RAG traci zaufanie:
- zrodla sa schowane,
- odpowiedzi low-confidence wygladaja tak samo jak grounded,
- fallbacki sa niejasne,
- user nie ma dobrej sciezki odzysku.
Dla mnie trust UX jest czescia jakosci RAG. Nie osobnym etapem polerki.
User powinien rozumiec:
- z czego system skorzystal,
- czego nie umial potwierdzic,
- i co moze zrobic dalej.
To zwykle oznacza:
- source links blisko waznych claimow,
- widoczna sciezke "nie wiem",
- sugestie doprecyzowania przy niskiej pewnosci,
- i uczciwe fallbacki dla timeoutu albo braku kontekstu.
Jesli UI ukrywa niepewnosc, system uczy usera zlej lekcji. User przestaje ufac nie dlatego, ze system pomylil sie raz. Przestaje ufac dlatego, ze wygladal na pewnego tam, gdzie pewny byc nie powinien.
Dlatego nie oddzielam jakosci retrievalu od jakosci UX. W realnym uzyciu to sklada sie do jednego pytania:
Czy user moze zaufac tej odpowiedzi na tyle, zeby na niej dzialac?
Warstwa 5: bez eval loop nie ma produkcji
To jest warstwa, ktorej najbardziej brakuje w publicznych projektach RAG.
Wiele zespolow mowi, ze "przetestowalo". W praktyce oznacza to zwykle, ze zadali kilka pytan recznie.
To nie wystarcza, kiedy:
- zmienia sie prompt,
- zmienia sie model,
- zmieniaja sie dokumenty zrodlowe,
- zmienia sie chunking,
- albo dochodzi nowa regula retrievalu.
Jako minimum chce widziec:
- benchmark set z realnych pytan,
- sposob na ocene trafnosci retrievalu,
- grounded answer check,
- budget latencji per etap,
- i widoczny fallback rate.
Nie potrzebujesz wielkiej platformy, zeby zaczac. Trzydziesci realnych query daje wiecej wartosci niz sto opinii.
Celem nie jest idealny pomiar. Celem jest mozliwosc powiedzenia:
- ta zmiana poprawila retrieval,
- ta zmiana pogorszyla grounded answers,
- ten prompt zwiekszyl fallback rate,
- ten model podniosl koszt bez poprawy zaufania.
To dla mnie znaczy "production-minded".
Gdzie Next.js 16 naprawde pomaga
Next.js nie rozwiazuje RAG za Ciebie. I to jest dobra wiadomosc.
Daje Ci czysta powloke do ustawienia granic:
- App Router dla stabilnej struktury aplikacji,
- Route Handlers dla zmiennej pracy AI,
- jawne cache i revalidation controls,
- i dobry fit do streamingu, jesli tego potrzebujesz.
W Next.js 16 najwazniejsza lekcja nie brzmi "uzyj tego jednego patternu RAG". Brzmi:
Badz jawny w tym, co jest static, co jest dynamic i jaka swiezosc danych ma znaczenie.
To zwykle oznacza:
- static albo revalidated content tam, gdzie dane moga byc cachowane,
- dynamic answer routes tam, gdzie user input i swiezosc steruja zachowaniem,
- i czysty podzial miedzy ingest/admin flow a public answer flow.
Jesli do streamingu uzywasz Vercel AI SDK, route-handler side moze byc prostszy. Ale wybor narzedzia ma mniejsze znaczenie niz granica systemu.
Next.js daje Ci application shell. Nie daje Ci:
- jakosci retrievalu,
- eval coverage,
- provenance rules,
- ani trust UX.
To nadal jest Twoja robota.
Najmniejsza bramka release'u, ktora ma dla mnie sens
Zanim nazwalbym RAG "production-ready", chce zobaczyc to wszystko:
- Znana sciezke ingestii z metadanymi i zasadami swiezosci.
- Benchmark set z realnych pytan userow.
- Trace record dla kazdej sciezki odpowiedzi.
- Low-confidence albo refusal state w UI.
- Budget latencji, ktory ktos naprawde obserwuje.
- Czlowieka odpowiedzialnego za jakosc zrodel i zachowanie systemu.
To nie jest enterprise theater. To jest minimalna struktura, ktora zatrzymuje dryf systemu w strone folkloru.
Bez tego zespoly prowadza w kolko to samo spotkanie:
"Model wydaje sie gorszy niz tydzien temu."
To zdanie zwykle znaczy:
- nikt nie mierzyl retrievalu,
- nikt nie sledzil sciezki odpowiedzi,
- i nikt nie wie, czy regresja przyszla z modelu, promptu czy danych.
Co powiedzialbym founderowi, ktory chce shipnac RAG teraz
Nie pytaj najpierw: "Ktory model wybieramy?"
Zapytaj:
- z jakiego evidence system bedzie korzystal,
- skad bedziemy wiedziec, ze korzystal z dobrego evidence,
- co user zobaczy, kiedy pewnosc jest niska,
- i jak wykryjemy regresje po wdrozeniu.
Jesli umiesz odpowiedziec na te pytania, wybor modelu stanie sie prostszy. Jesli nie umiesz, to wybor modelu jest nadal przedwczesny.
To jest dla mnie prawdziwy ksztalt produkcyjnego RAG w Next.js. Nie sprytny prompt. Nie screenshot z vector database.
System, ktory umie wyjasnic:
- dlaczego odpowiedzial,
- z czego skorzystal,
- kiedy powinien odmowic,
- i skad zespol wie, ze jakosc spadla.
To jest bar, ktory mnie interesuje. I to jest bar, ktory chce, zeby moje portfolio pokazywalo.
Najwazniejsze wnioski
- Wiekszosc problemow z RAG zaczyna sie przed promptem: psuja sie ingestia, retrieval, swiezosc danych i UX zaufania.
- Jesli nie potrafisz obejrzec sciezki odpowiedzi przez evale i trace'y, to nie kontrolujesz systemu.
- W wrazliwych domenach provenance i refusal behavior sa wazniejsze niz ladnie brzmiacy output.
- Next.js daje czysta powloke dla RAG, ale prawdziwa praca dzieje sie wokol retrievalu i zaufania usera.
Zrodla
Chcesz taki poziom jakosci w swoim produkcie?
Pomagam zespolom wdrazac AI feature'y, ktore sa szybkie, wiarygodne i gotowe na produkcje.